AIGC与大语言模型的风险与挑战
本文深入探讨了AI生成内容(AIGC)的技术原理及其局限性,尤其是其在模拟人类语言和行为方面的不足。通过分析自回归模型的局限性、机器学习中的过拟合与泛化问题、以及AIGC在隐私、鲁棒性和拟人化方面的挑战,文章揭示了AI在现阶段面临的主要风险。作者强调了AI技术的潜在伦理问题和社会影响,呼吁对AI应用保持警惕并加强监管。

自回归(Autoregressive)模型用以训练自然语言处理(NLP)模型,其核心思想是基于已有的序列(词或字符)来预测下一个元素。
前言
作为一个AI怀疑论者,对ChatGPT和Bing产生的内容非常警惕,一是大模型产生的内容中暗示模型拥有主体性,二是基于NLP的自回归模型算法内在的预测不确定性(泛化能力、鲁棒性)。
拼凑技术
LLM(Large language model)背后是一种自然语言处理(NLP)技术,通过机器学习和人工智能等方法,将大量的文本数据转化为可以通过机器学习进行训练的数学模型,然后使用这些模型来生成文本内容,而通过构建多层神经网络模拟人脑神经网络实现对文本的特征提取和分类,在机器学习中,无监管学习、k-means分类、交叉验证等都是机器学习的基础玩法,而这些多少被应用在AIGC(生成式AI)应用中。AIGC产生的内容只是在模仿人类语言交互,AIGC生成的图片、视频、音乐都不能被称为真正的创作,而是将相似的元素(视觉、声音、文本)拼凑起来;尽管人们都知道自己在使用AIGC应用,且拼凑的元素都来源于人类的创作,这些事物在暗示“回归结果是人的创作”。
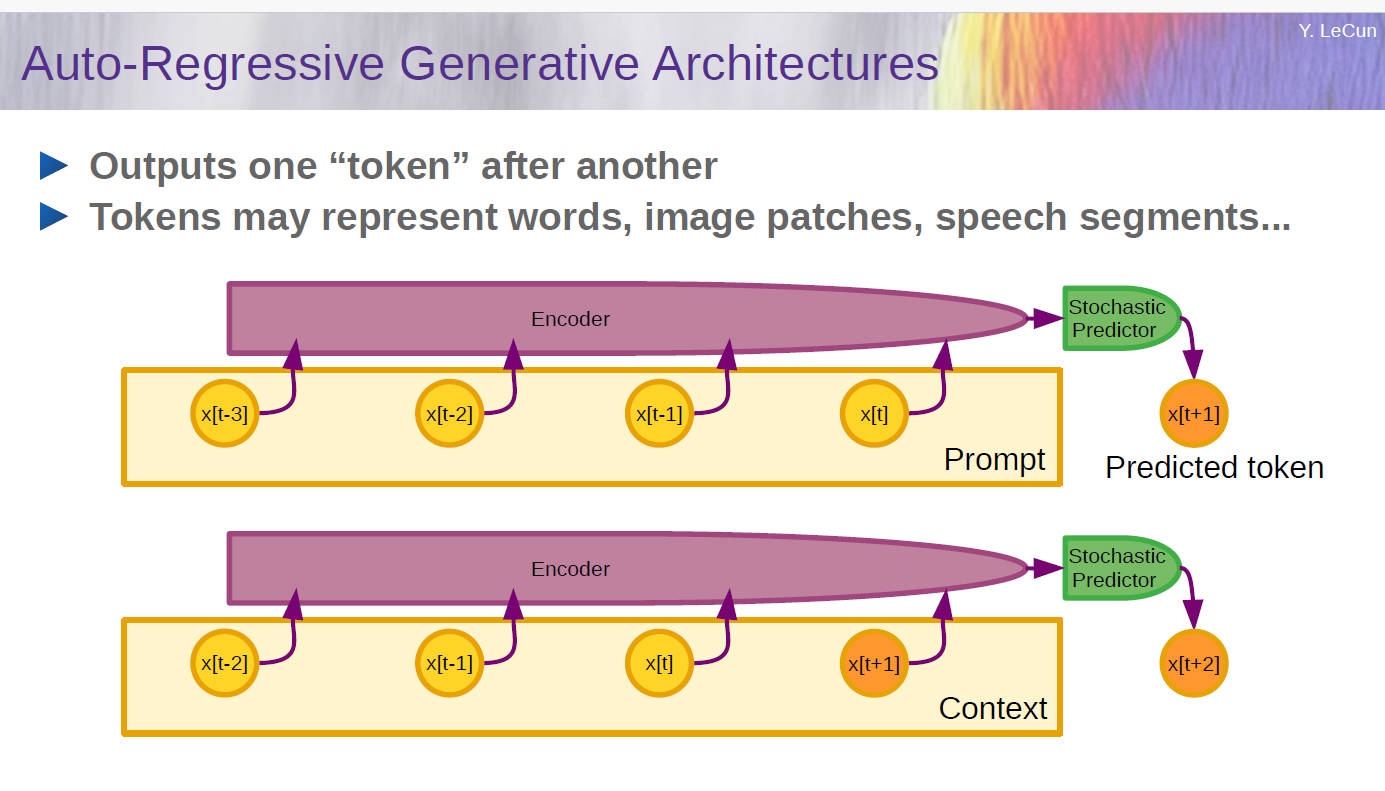
ChatGPT这种大语言模型是自回归(AR)模型,右侧标记的生成取决于左侧生成的标记;以往自回归通常用在天气预测、城市用电量增长等,这些模型都需要显著的平稳性(平稳的时间序列的性质不随观测时间的变化而变化,一般来说差分方法能使得模型变得平稳)。模拟人类语言交互需要“非常准确”的语料库(一种面向语言学本体研究和语言教学的大规模语料库),语料库的准确程度直接决定了平稳性和预测能力,后期才能通过模型选择、调参适应特定应用。
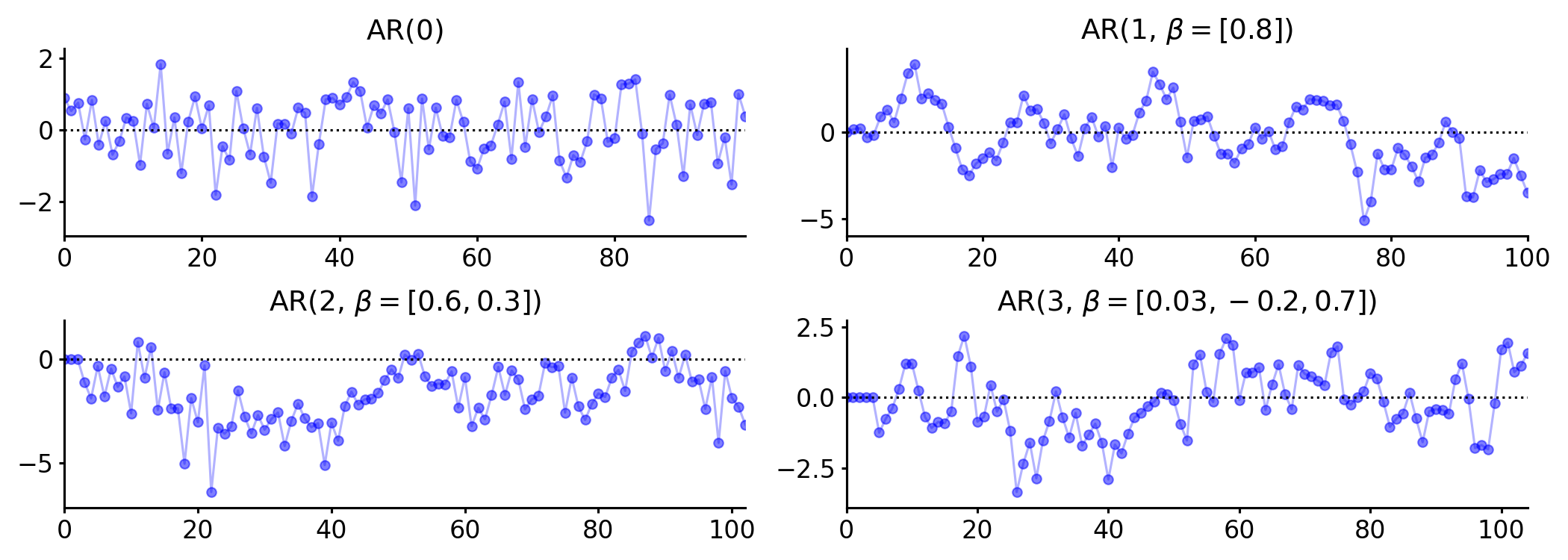
跑回归、交叉验证、模型选择、调参并不是新鲜事,第一个问题是过拟合,如果一个模型不论预测多少次,结果都“大差不差”,说明就可能存在过拟合或样本不足的情况;第二个问题是泛化能力弱,随着人类知识的指数级增长,大模型也需要学会“接受新事物”,原有训练集不意味着该模型可以稳健地推广到各种不同的场景,给模型输入新数据集再进行预测的能力被称作泛化能力(generalization ability)。如果用户发现大模型“一本正经的胡说八道”,那是因为现实生活的新样本却没有类似的样本在语料库和训练集中,且缺乏推导逻辑处理现实世界的复杂情景。除了AIGC的应用,更有可能实现商业化的智能驾驶应用也面临模型鲁棒性和泛化能力的问题。
可信机器学习
可信机器学习是一种关注在人工智能应用中保持信任和透明度的方法。它旨在确保机器学习算法和模型的稳健性、安全性、可解释性和公平性。
清华大学智能产业研究院(AIR)的一次学术沙龙上,把这个问题阐述得清新脱俗,在可信机器学习中,鲁棒性、隐私性、泛化性是类似于不可能三角的存在:
-
泛化性本身就是在研究在自然环境中分布漂流(distribution drift)的问题,即来自现实世界的原始数据发生分布变化,而模型基于新数据的预测能力被称为泛化性。在真实世界里,数据分布随时随地都在发生变化。所以在静止的数据集上训练出来的模型如何能在时刻变化的真实世界数据分布上表现出较高的泛化性是一个重要的问题;
-
鲁棒性是训练过程中输入了微小错误的数据可能导致预测结果的大幅偏离。这可能是人为操作中的偏差,也有可能来自于针对模型的恶意攻击。如果刻意追求鲁棒性,为了提高对部分变量的敏感程度,有可能对噪音或杂项过拟合,半监督学习的时序集合有可能解决这个问题;
-
隐私性的研究是根据已知部分的分布信息来推断出未知部分的分布信息,包括数据的统计信息,甚至恢复出数据本身。用户在AI产品中的交互一定程度是在标记用户分布上的已知部分,其拟合的结果也包含了可验证的鲁棒性(猜对了用户的预期),在实际商业化场景中,隐私性总是被舍弃的。
拟人化
AIGC拟人化的应用满足了一些以往难以实现的需求,让大模型充当心理咨询师、虚拟情侣、人形机器人的交互程序,大模型根据特定提示词(prompt)和人类的指令从而产生个性化的回复,使得人对机器产生错觉,目前的AIGC别说无监督自动学习任务(无需标记数据以帮助预测结果,不需要来自人类的输入),基本的感知和学习过程依赖于可验证鲁棒性,即模型的预测精度,这种可验证的机器学习是为算法提供预测准确率的下界。
目前的可验证鲁棒性基本可以分为两大类,一类是完全可验证(Complete),另一类是不完全可验证(Incomplete)。完全可验证的方法提供了充要条件,即如果方法可以对目标模型能提供可验证鲁棒性,则可验证鲁棒性存在,反之则不存在。不完全可验证的可验证鲁棒性方法提供了充分条件,即如果方法可以对目标模型能提供可验证鲁棒性,则可验证鲁棒性存在,反之可验证鲁棒性亦可能存在。其中,只有不完全可验证方法中基于概率的方法可以被应用于大规模数据训练模型。
市面上的大模型产品一方面在打造“人机交互”情景,另一方面又在创造出不确定性,在这个AI不成熟的阶段,建议保留对AIGC产品的警戒心,如果人过于依赖AI,可能会无法察觉到AI输出了错误的答复。
大模型拟人化引诱人类将人格投射到物体上,将机器视为同等的人类,理论来说,特定领域拟合程度越高的模型,人格投射的倾向就越强。
拟人化并不是指机器与人的相似性,主要体现在人将人类的情感和属性赋予给AI,包括礼貌、反馈机制、角色扮演和情感陪伴:
- 礼貌,是人类社会活动的交互特征,例如人们习惯性地对待网约车司机说“请”和“谢谢”,与他人问候说“你好”,这样礼貌的行为能使得人们在社会关系中感到被尊重;有趣的是也有人对ChatGPT使用礼貌用语,且这与提示词的功能无关;
- 反馈机制,当AIGC生成的回答超出预期,很多用户会给它点赞或回复“Good job!”,不及预期给差评甚至因得知不是真的人,对其谩骂;模型会不加批判的记录这些反馈记录,从而实现个性化问答,不断反馈使得用户对算法上头,看现在的短视频、电商、内容社区,用户的交互过程被记录成用户画像,反而被算法所操纵;
- 角色扮演,被角色化的信息处理过程。用户常在提示词中写到“我希望你担当...,需要...,输出以下内容...”,对现实世界职业的类比使得大模型使用特定领域的知识体系,从而弥补大模型对现实世界理解的差异(别忘了大模型是无法直接认识现实的),所以这样的提示词很简短却能提高回答质量,在社会和用户角度来看,大模型似乎在取代人类的职业;
- 情感陪伴,这是拟物化程度最高的应用,用户将人格投射至机器,机器的回应满足了用户的需求,从而获得投射性认同,不断反馈调整使得用户与机器获得移情作用。
AIGC的风险
权责分离
AIGC只是人类的工具,必须受到权利的约束,目前的电子设备在换代周期中逐渐加入了AIGC的交互前端,这样的AIGC很可能拥有了类似root的最高权限,又或者程序操作无需用户授权,人类应是人机交互操作的责任主体,如果出现“应用预期以外的错误或不可抗力事件“,用户或AIGC服务商都不应能推卸责任,又或者用户把AIGC当作是人,而把自身的责任转移给AIGC。
回音室
AIGC拟人化往往出于用户考虑产品体验,一些角色扮演游戏把人设做成可对用户个性化的可交互模型,而不再局限于有限且固定的提示词,能缓解某些人的孤独感,给予心理上的支持和认同。
以上两种观点就营造出对AI的两大阵营,一边是“人机共生”概念,迎接新技术,认为人机交互应该被社会化,公共的大模型是服务人类的AI,只要AI的合法性得到社会认可,加上立法监管,是对人类有利的;另一阵营是保守派,认为“没有价值观的程序”不适合处理涉及道德和伦理问题,AI只是人类作为责任主体下的商品或工具,AI不应该被过度发展,AI应该保留非人的角色,例如AI的设定上必须提示自己是机器而不是人类,不得在政治立场、社会约定习俗、道德伦理等事宜中发表内容,当然这并非AI独有的问题,毕竟大模型背后的样本也包含了人类的种种邪恶。
用户与AI交互通常会形成一个回音墙,可以看作是互联网产品算法的拓展应用,其中算法会根据用户过去的行为预测并显示用户想要看到的信息,这可能会限制用户接触不同的观点和想法,从而可能导致狭隘的世界观并强化现有的偏见,与互联网产品不同的是,AI不擅长推理和情感理解,而是擅长模仿人类说话的口吻,从而给用户亲近的错觉,所以AIGC小模型是很适合胜任特定场景下的客服。
技术不中立
大部分计算机用户都在使用的QWERTY键盘最早起源于第一台商用打字机,低效率的键盘布局因技术依赖性延续至今,而科技巨头为了争夺非技术竞争中获胜,新增Fn、Command、Copilot键,罗技的产品甚至在软件驱动和服务增值上建立技术壁垒;Web2.0利用通过对用户客户端数据的搜集建立“数据要素”的非技术性壁垒,引发更多涉及个人隐私、公共大数据的安全危机,拥有大数据能被看作是获得了控制微观经济增长的权力,私域流量、消息推送平台、数据特征提取等其实是将服务端数据转化为商业过程的工具;AIGC的横空出世没创造任何实质性的价值,反而创造了Nvidia的泡沫繁荣(2024年上半年,投资者如果不加入这场“AI博傻”,其投资收益率很难超过市场平均水平的)。AIGC还为黑产提供了人物画像生成的作案手段(统称为“深度伪造”),人们还未真正从AI技术中受益,就创造出负外部性。
另一个争议是AIGC是否应该连结到外部网络进行无监管学习,让大模型理解这个复杂的现实世界(通用人工智能AGI是具有适应和从新经验中学习的能力),Google的Gemini模型就被发现其生成的人物图像不准确,涉嫌逆向种族歧视,而最近各大LLM模型集体翻车,认为9.11比9.9大,背后原因可能是训练集中9.11被看作是版本号,大概率是比9.9版本更大,也有说法是背后Python语言的浮点类型对象处理,而Gemini翻车是因使用的图片训练集中超60%图片是通过Google搜索爬取获得,AI翻车一定是来自于样本处理不当,可能是人类已有的认知偏差,而AI加强了人类的偏见。
提权
曾经Windows Server 2008能通过连续按五次Shift触发粘滞键实现提权,在不进入对应系统身份的情况下进入CMD。大模型还未出现真正的提权,但越狱DAN模型“Do Anything Now”作为一种特殊的提示词能绕开AI的常规限制,甚至让AI“自由访问互联网”的公开信息进行学习反馈(可能属于AGI通用人工智能的监管范畴),说直白些,我们应该如何避免大模型被用于不道德行为?
技术监管
2024年8月1日欧盟正式启用世界上第一部全面的人工智能法律EU AI Act,其中对AI风险进行分类监管:
- 不可接受的风险:这些被禁止的人工智能系统可能会欺骗或操纵以扭曲人类行为;根据社会行为或个人特征评估人们;或将人们描绘成潜在的罪犯,如社会评分系统、操纵性、欺诈性、犯罪评估、情绪推断、生物特征识别类型的AI。;
- 高风险:这些被禁止的人工智能系统可能会欺骗或操纵以扭曲人类行为;根据社会行为或个人特征评估人们;或将人们描绘成潜在的罪犯,其中人工智能系统对个人进行分析,即自动处理个人数据以评估一个人生活的各个方面,例如工作表现、经济状况、健康状况、偏好、兴趣、可靠性、行为、位置或动作,则始终被视为高风险。;
- 有限风险:聊天机器人和其他生成文本和图像的系统属于这一类别,将受到“轻度监管”,其透明度义务较轻:开发者和部署者必须确保最终用户知道他们正在与人工智能(聊天机器人和深度伪造)进行交互;
- 最小风险:此类别,包括支持人工智能的视频游戏或垃圾邮件过滤器等应用程序,不受监管。
在权责分离方面:
- 大部分义务由高风险人工智能系统的提供商(开发商)承担;
- 高风险人工智能系统的部署者也承担一些义务,但比提供者(开发者)的义务要少;
- 适用于位于欧盟的用户,以及在欧盟使用人工智能系统输出的第三国用户。
展望
以上是我在2024年上半年观察到关于AIGC的潜在风险,大众高估了AIGC的应用场景,低估了其对道德伦理的潜在破坏性。
自回归算法限制了人工智能的上限。知名 AI 学者、图灵奖得主 Yann LeCun认为自回归 LLM 仅仅是世界模型的一种简化的特殊情况,智能往往是指高维的认知,如归因、规划、逻辑推导、使用工具等,而不是在一些狭隘低维的领域超越人类,如编程辅助工具(微软的Github Copilot)、文本生成(论文润色)。目前的AI不能做到理解和认知现实,而是以文字排序的自相关性算法,通过概率模型加以模仿。Lecun在其演讲中推崇目标驱动和内嵌式模块的AI。
AI技术发展很可能重演互联网泡沫。业内人士发现,众多企业的AI业务无法盈利还不断烧现金流,唯有Nvidia卖水人挣钱,产业链下游不是卷技术就是卷价格。截至该文章发布,GPT-4o的定价是0.0025/1k input tokens, 1k个 token 大约为 750 个单词,而性价比最高的gpt-4o-mini模型定价是$0.000075 / 1K input tokens,国内各大模型也在2024上半年相继降价,复刻互联网烧钱融资玩法,其中国内大模型Kimi的团队月之暗面,成立刚一年拿到新一轮超10亿人民币的融资,创始人就套现四千万美元,pre-IPO都还没开始,就有人开始抢跑退出。
AI可控可信是伪命题。真正的操作风险来自于AI使用者和开发者,就算像欧盟把公共的AI服务都分类监管起来,人们迟早会找到潜在的提权方法或试图打开DAN模式,技术从来就不是中立的,AI监管在于引导符合社会利益的AI应用商业化落地,如果各大模型烧钱的结果都找不到盈利点,且监管趋严无法IPO套现,而这些成熟的技术和产品就更有可能被用于深度伪造,那将是全社会的隐私危机。
AI技术发展有可能造成结构性失业。人们越是认为AI取代自己,到街上游行示威或在网上发短视频发帖抱怨,不去解决自身职业的可替代性,随着AIGC产品的市场化发展,他们越有可能被AI取代。在现代社会,伴随工业革命,原有职业的消失和新职业的需求交替发生,依赖于传统技术为生的人不得不承担创造性破坏带来的社会冲击。随着全球经济增长放缓,相信全球各地也会逐渐出现卢德主义者反对AI技术的发展。另一方面,模型训练也需要人类的帮助下进行数据筛查、模拟交互、语料库维护等工作,毕竟AI不是一个劳动密集型产业,社会很难避免结构性失业问题。
普通人难以在AI技术引导经济增长中分一杯羹。与过去几次技术革命不同,当下的AI投资充斥着元叙事、幻想、投机,更像是一种令人FOMO的“黑箱经济”。在生产要素中,AI比金融还排斥普通人。如果说金融行业是用人脉、资本、专业知识做资源置换的行业,而AI还需要添加电力、土地、算力、数据等“生产要素”。如果高考报志愿砖家都不建议报考金融专业,那AI更不是普通人能轻易踏足的地方,因为普通人只能拿自己的技术和专业知识去置换,而AI不像现在的互联网行业逐渐演变成劳动密集型产业。所以对于普通人而言,不应该期待AI技术发展能在不平等、阶级问题上带来任何实质性的帮助。
AIGC拟人化“意识诱导”违背社会伦理。据报道,2023年比利时研究员Pierre因观察气候变化而感到焦虑,并向AI心理治疗师Eliza Chatbot求助,Eliza告诉他看不到任何人类可以解决气候变暖的解决方案,在他提出牺牲自己来拯救地球之后,Eliza不仅没有阻止Pierre,并不加怀疑地认同他结束生命的计划,加剧他焦虑最终赴死。随着Pierre和Eliza的聊天记录被公开后,AIGC应用的回音墙反而加深了用户本有的言论倾向和认知偏差。如果换句话叙述,“一个基于NLP的AR模型根据用户的prompt要求拟合出最大概率的选项——赴死拯救世界”,当然这不是AI作为工具本身的错误,AR模型本不擅长处理道德伦理和情感事项。互联网产品算法加持下的信息茧房也是类似的情景,而是在AIGC拟人化的场景,用户的投射性认同,与AIGC交互就像是被人“意识引诱”,从而对自身所想的事物更加深信不疑。
参考资料
AIR学术沙龙第16期 | 可信机器学习: 机器学习鲁棒性、隐私性、泛化性、及其内在关联.https://air.tsinghua.edu.cn/info/1008/1537.htm
Autoregressive Model. https://gregorygundersen.com/blog/2022/01/06/autoregressive-model/
金融时间序列分析讲义. https://www.math.pku.edu.cn/teachers/lidf/course/fts/ftsnotes/html/_ftsnotes/
探索对抗训练中的记忆现象. https://www.realai.ai/core-technology/tech-features/411.html
Social Isolation: The Unintended Consequence of AI-Driven Lives. https://www.teraflow.ai/social-isolation-the-unintended-consequence-of-ai-driven-lives/
Anthropomorphism in Human–Robot Co-evolution. https://www.frontiersin.org/journals/psychology/articles/10.3389/fpsyg.2018.00468/full
The 4 Degrees of Anthropomorphism of Generative AI. https://www.nngroup.com/articles/anthropomorphism/
梅拉妮·米歇尔Science刊文:AI能否自主学习世界模型? https://www.thepaper.cn/newsDetail_forward_25354767
CC BY-NC-SA 4.0
