机器学习丨沪深300估值聚类和主成分分析
对沪深300的PE TTM进行描述性统计、OLS回归、k means聚类、层级聚类和主成分分析。
主成分分析图
前言
万得Wind的F9有指数历史PE的分析图,其中就有一项是PT-TTM和一年后收益率的散点图,但单纯的散点图是揭示不了任何事物,它的相关性,以及回归R^2都不得而知,只能肉眼观测。
继上篇博文沪深300估值研究:岭回归、拉索回归和交叉检验,揭示了沪深300的估值与长期工业利润率的相关因素,本文研究沪深300估值,引入新的研究方法,聚类(Cluster)和主成分分析(PCA),因为传统的回归和相关性分析已经并不实用。
描述性统计
library("readxl")
data = read_excel("000300.SH-历史PE_PB-20240105.xlsx", sheet = "市盈率TTM")
library("plotly")
fig <- plot_ly(x = data$市盈率TTM, type = "histogram")
fig
quantile(data$市盈率TTM, c(0.025, 0.975))
library(moments)
mean(data$市盈率TTM)
sd(data$市盈率TTM)
skewness(data$市盈率TTM)
kurtosis(data$市盈率TTM)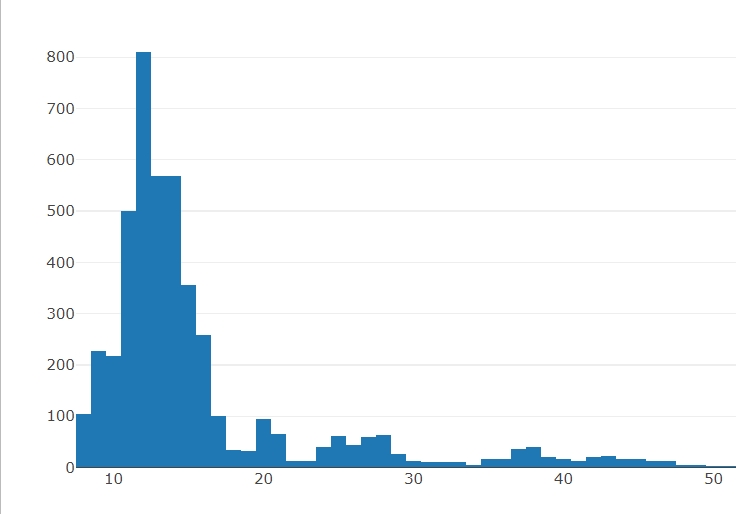
| Quantile | 0.025 | 0.975 |
|---|---|---|
| PE | 8.54 | 41.085 |
主要看2.5%的分位值,意味着历史底部的水位。
| mean | stdev | skewness | kurtosis |
|---|---|---|---|
| 15.75 | 7.73 | 2.25 | 7.70 |
估值的kurtosis大于5,典型的肥尾分布,尖峰肥尾,肥尾分部的两尾部分明显比正态分布要大。
对于沪深300而言,“相对低估值”其实没有意义的,导致无法通过简单的低估和高估进行获利,很多人看到这里会觉得指数投资已死,但也不尽然,接下来进行OLS回归和相关性分析因果和相关性。
传统回归
# readxl包读取xlsx
library("readxl")
df = read_excel("000300.SH-历史PE_PB-20240105.xlsx", sheet = "历史估值对应未来1年收益率统计")首先对传统回归,很轻易得到-0.67的回归系数,而在简单的OLS回归中,决定系数为-9.19,而R^2为0.45,很显然存在遗漏变量,其实市盈率TTM和一年后的收益率并不存在直接的联系,所以在实证过程中我们很容易就放弃了通过工具变量等方法的研究,因为这些数据存在的多重共线性问题。
lm = lm(`一年后收益率` ~ `市盈率TTM`, data = df)
summary(lm)
cor(df[, c("市盈率TTM", "一年后收益率")])
> cor(df[, c("市盈率TTM", "一年后收益率")])
市盈率TTM 一年后收益率
市盈率TTM 1.0000000 -0.6681169
一年后收益率 -0.6681169 1.0000000
library("ggplot2")
library("ggpmisc")
fig <- ggplot(df, aes(x = `市盈率TTM`, y = `一年后收益率`)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "blue") +
stat_poly_eq(formula = y ~ x, aes(label = paste(..eq.label.., ..rr.label.., sep = "~~~")),
parse = TRUE, size = 4) +
labs(title = "沪深300指数历史市盈率与未来1年收益率关系", x = "市盈率TTM", y = "一年后收益率") +
theme_bw() +
theme(plot.title = element_text(hjust = 0.5))
fig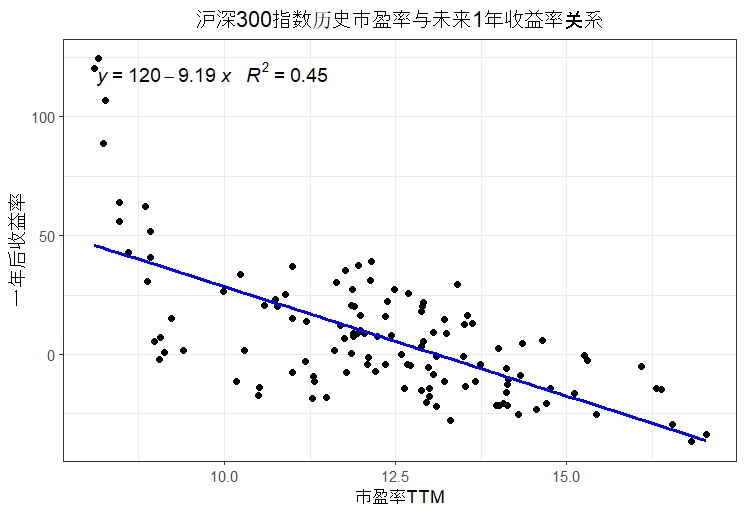
简单OLS和相关性并不能解释其中的联系,因为存在“异常值”,基于实证主义和既定事实,我们当然是不能剔除偏离均值过多的数据,所以才需要聚类或分类分析。
k-means聚类
K-means是基于欧式距离的聚类算法,认为两个目标的距离越近,相似度越大,相似性由欧几里得距离计算。
K-means聚类的结果是k个聚类中心点,这样聚类中的所有点与其中心点的距离都比与其他任何中心点的距离近。
library(cluster)
kmeans_2 <- kmeans(x, centers = 2, nstart=50)
kmeans_3 <- kmeans(x, centers = 3, nstart=50)
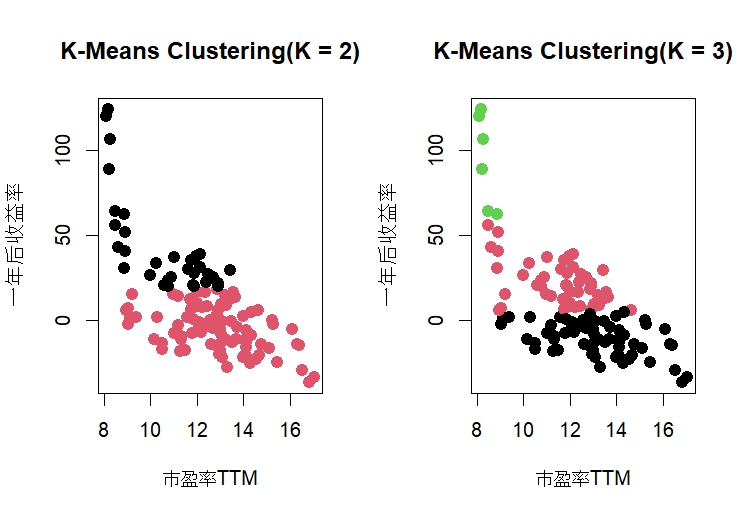
par(mfrow = c(1, 2))
plot(x, col = kmeans_2$cluster,main = "K-Means Clustering(K = 2)", pch = 20, cex = 2)
plot(x, col = kmeans_3$cluster,main = "K-Means Clustering(K = 3)", pch = 20, cex = 2)
kmeans_2$tot.withinss ## 输出的是组内总方差之和sum of square
[1] 41314.72
kmeans_3$tot.withinss
[1] 17613.71
kmeans(x, centers = 4, nstart=50)$tot.withinss
[1] 9722.441理论上组内总方差之和越小越好,但考虑到k若为4和5,组内总方差的减少越来越少,为了避免过拟合的情况使用k=3。
hc.complete <- hclust(dist(x), method = "complete")
plot(hc.complete, main = "Complete Linkage",
xlab = "", sub = "", cex = .9)
cutree(hc.complete, 2)
xsc <- scale(x)
plot(hclust(dist(xsc), method = "complete"),
main = "Hierarchical Clustering with Scaled Features")当k=3聚类,绿色点主要分布在2014年,而右下角的黑色点主要分布在2015年,这些都不是“异常值”,所以分为以下三类:
- 在PE-TTM为10以下杀估值,获得估值修复行情的收益
- 右下角黑色点为2015年股灾影响,杀估值更杀收益率
- 而中间红色和黑色的分界线近似为0,说明在估值平稳期间是没有显著“买入并持有”策略获利的机会
层次聚类
层次聚类的凝聚算法通过计算每个类别内所有数据点与其他类别数据点之间的相似性,以确定它们之间的距离。在每一次迭代中,选择最为相似的两个数据点或类别,将它们合并为一个新的类别,形成聚类树。相似性的度量通常基于距离或相似性指标,较小的距离或较高的相似性值表示较高的相似性。这一过程不断重复,直到所有数据点被合并为一个整体聚类或满足预定的停止准则。这种方法允许以层次结构的形式揭示数据点之间的关系,并可通过树状图(树状图谱)呈现,其中有以下三种:
-
Single Linkage(单链接): Single Linkage倾向于将两个最接近的数据点所在的类别合并在一起。它的确有可能将相距较远的点组合在一起,因为它只关注两个类别中最接近的数据点之间的距离。
-
Complete Linkage(完全链接): Complete Linkage倾向于将两个类别中最远的数据点之间的距离作为类别间的距离。如果有一个类别中有两个数据点距离另一个类别中的两个数据点较远,那么这两个类别就会被分成两个小组,较远的组将被再次分类。
-
Average Linkage(平均链接): 在Average Linkage中,不是直接计算两个组之间的距离,而是计算两个组中所有数据点之间的平均距离。然后,用这个平均距离作为两个组之间的距离。这样,它考虑了所有数据点之间的关系,而不仅仅是最接近的或最远的两个点。
我们想将相似的数据尽可能分类,选择Complete Linkage:
hc.complaete <- hclust(dist(x), method = "complete")
plot(hc.complete, main = "Complete Linkage",
xlab = "", sub = "", cex = .9)
cutree(hc.complete, 2)
xsc <- scale(x)
plot(hclust(dist(xsc), method = "complete"),
main = "Hierarchical Clustering with Scaled Features")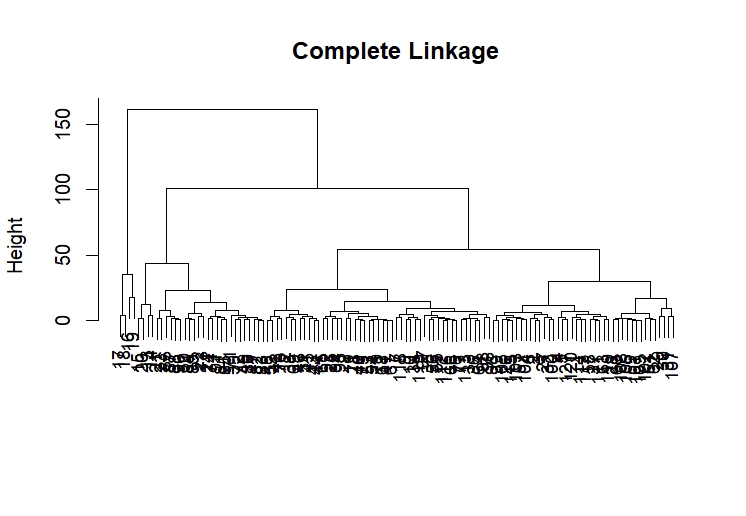
结果是它将2015年高pe数据单独分为一类,结果和k-means相似。

通过scale函数对特征进行标准化,确保所有特征在聚类过程中具有相似的尺度。标准化是一种数据预处理技术,通过将特征进行缩放,使其具有相同的平均值和标准差,从而消除了尺度对聚类结果的影响。
通过以上聚类,我们很容易得到将市场高估值带动收益率的情况分为一大类,但其对总方差的贡献如何?我们又如何看待大部分时间平稳的估值?这就需要对数据进行降维分析——PCA主成分分析。
主成分分析
主成分分析PCA,是利用正交变换来对一系列可能相关的变量的观测值进行线性变换,从而投影为一系列线性不相关变量的值,这些不相关变量称为主成分。
pr.out <- prcomp(x , scale = TRUE)
Cols <- function(vec) {
cols <- rainbow(length(unique(vec)))
return(cols[as.numeric(as.factor(vec))])
}
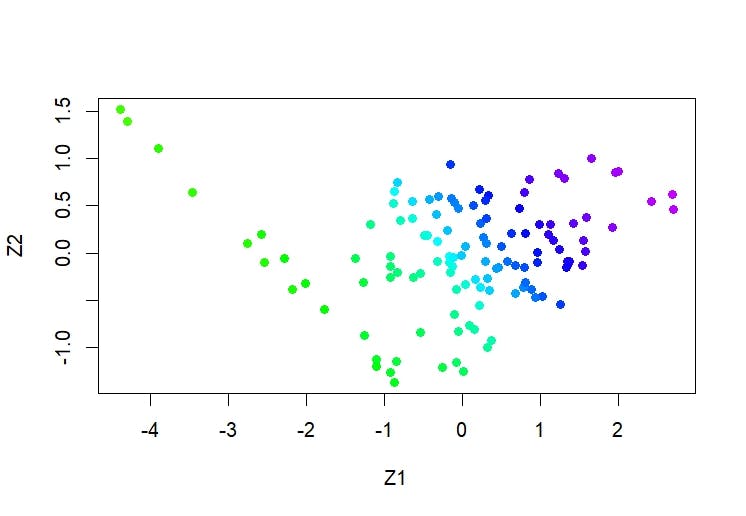
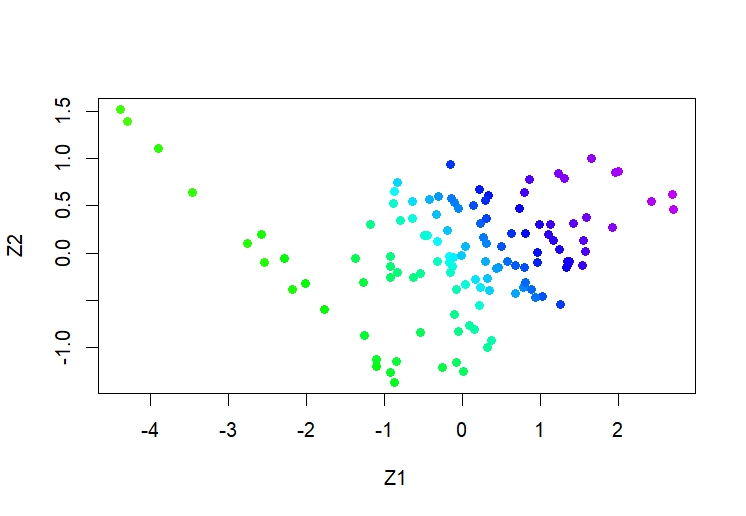
plot(pr.out$x[, 1:2], col = Cols(x), pch = 19,
xlab = "Z1", ylab = "Z2")
summary(pr.out)
Importance of components:
PC1 PC2
Standard deviation 1.2916 0.5761
Proportion of Variance 0.8341 0.1659
Cumulative Proportion 0.8341 1.0000从结果上来看,标准差较小说明拟合优秀,第一主成分(PC1)的方差比例为83.41%,PC2解释了16.59%。这表示PC1在解释数据变异性方面起到了更重要的作用,累积方差是指在主成分的顺序排列中,前n个主成分解释的方差比例的累积。在这里,PC1和PC2的累积方差比例分别为83.41%和100%。
-
拟合优秀。当标准差较小时,说明数据点相对于主成分的投影较为集中,这通常被认为是一个拟合优秀的指标。在这里,PC1解释了大部分方差,这可能导致较小的标准差。
-
如此高的累计比例PC1正是说明不论PE-TTM如何排序,大部分时间的估值的变化都对对未来一年收益率的变化不构成显著的影响,只有极端估值波动才有机会,PC2说明估值平稳的情况下,对未来1年收益率也无显著影响。
图形上看,居然发现抄底杀估值和追逐估值增长同样对未来一年收益率有积极影响。
pve <- 100 * pr.out$sdev^2 / sum(pr.out$sdev^2)
par(mfrow = c(1, 2))
plot(pve , type = "o", ylab = "PVE",
xlab = "Principal Component", col = "blue")
plot(cumsum(pve), type = "o", ylab = "Cumulative PVE",
xlab = "Principal Component", col = "brown3")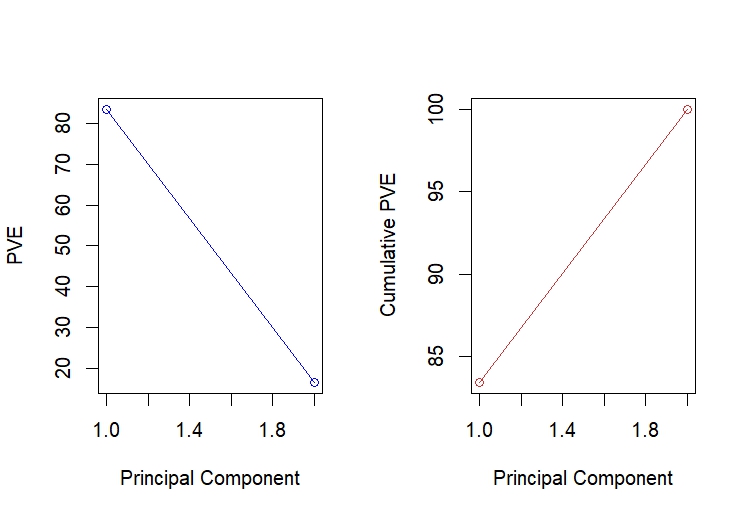
当PVE下降而Cumulative PVE上涨时,通常说明高阶主成分对总方差的贡献较小,但累积的效果仍然是积极的,而前几个主成分能够较好地捕捉数据的变异性,所有的主成分解释所有的方差,说明估值与收益率之间也存在“噪音市场”,也就是说估值的变化大部分时间对未来1年收益率是不敏感的,和上边PAC图一样,只有大幅度杀估值和追高估值才会有正收益,中间区间更多是噪音。
结论
- 在指数投资的角度,相对低估值没有意义,估值的剧烈变化是有意义的
- 估值和未来一年收益率存在共线性或噪音市场,说明沪深300仍然是一个偏低效的市场。
- 估值的肥尾分布导致大部分时间的买入并持有策略的收益率更加不确定,指数投资更需要择时。
参考来源
An Introduction to Statistical Learning with R(作者非常喜欢的统计学书)
数据来源:Wind
CC BY-NC-SA 4.0
